PREMESSE PER L'UTILIZZO DEL DOM
Verificare il supporto e distinguere gli oggetti basici
Innanzitutto verifichiamo che il nostro browser supporti il DOM di
Livello 1.
Il modo tradizionale per far questo è rilevare la presenza dell'oggetto
(metodo) getElementById, definito dal W3C.
Il codice sarà di questo tipo:
if (document.getElementById) {
// il browser supporta
// il DOM di livello 1 del W3C
}
else {
// il browser NON supporta
// il DOM di livello 1 del W3C
}
In realtà, questa rilevazione non garantisce di per sé che il browser
supporti tutte le specifiche, ma verifica semplicemente che l'oggetto in
questione sia presente. Prima di entrare nella descrizione dei
principali metodi e proprietà del DOM, occorre specificare con più
accuratezza la differenza tra element e node.
Un elemento (element) è contraddistinto da un tag, qualunque esso
sia. È facile quindi capire che può contenere altri elementi, si pensi
al tag TABLE, che si compone di righe e di colonne, le quali a loro
volta possono contenere altri elementi.
Il nodo (node) ha un significato semantico più ampio: oltre ad
includere nella sua definizione tutti gli elementi, un nodo può essere
anche un testo o un attributo, che, a differenza di tutti gli altri
nodi, non possono avere attributi e non possono contenere altri nodi.
Chiarito questo punto possiamo addentrarci nei dettagli del DOM
percorrendo i metodi, le proprietà, e le caratteristiche dei mattoni
costituenti il DOM stesso: document (l'elemento principale),
element e node.
L'OGGETTO DOCUMENT
Rappresenta l'elemento da cui tutti gli altri partono
Come appena accennato document è un elemento molto importante,
perché è quello in cui ogni altro elemento è incluso. Di conseguenza,
anche document corrisponde ad un tag, quello che contiene tutti
gli altri e che identifica una pagina per il Web: il tag <HTML>.
Detto questo passiamo a trattare i principali metodi di document,
che si possono dividere tra metodi che si occupano di recuperare
elementi nella pagina e quelli utilizzati per la creazione di nuovi
elementi.
Della prima sfera fanno parte:
Le differenze tra i due metodi sono evidenti: recuperare o un
elemento particolare o una famiglia d'elementi con le stesse
caratteristiche.
Passiamo ora ai metodi di document che si occupano di creare nuovi
elementi della pagina:
- createElement: il metodo permette di creare un nuovo elemento di qualsiasi tipo si
voglia. Ritorna un riferimento al nuovo elemento creato.
La sua sintassi
nuovoElemento = document.createElement("nome_TAG")
dove nuovoElemento è la variabile che conterrà il riferimento al
nuovo elemento creato e nome_TAG è il nome del tag di cui si vuole creare un nuovo elemento.
- createTextNode(): il metodo permette di creare un nuovo nodo di testo. Come prima
accennato, i testi sono nodi particolari che non possono contenere altri
nodi, corrispondono quindi agli ultimi anelli della catena del DOM. In
particolare, il metodo, restituisce un riferimento al nuovo nodo di
testo creato. La sua sintassi è:
nuovo_testo = document.createTextNode("testo_da_inserire")dove
nuovo_testo è la variabile che conterrà il riferimento al nuovo
nodo di testo e testo_da_inserire è la stringa di testo da inserire nel nuovo nodo.
Proviamo ad utilizzare questi metodi. Supponiamo di voler inserire un
nuovo nodo di testo, la sintassi da utilizzare sarà:
testo = document.createTextNode("Testo aggiunto dinamicamente!")Ma dove è il nuovo nodo di testo? In realtà il nodo non viene
visualizzato, almeno per ora. Questo ci fa intuire che c'è differenza
tra creare un nuovo nodo ed inserirlo nella pagina. Esiste tutto un set
di metodi che servono per "appendere" i nuovi nodi esattamente dove si
vuole.
Prima di giungere ai nodi, procediamo per gradi, e passiamo ad
element.
L'OGGETTO ELEMENT
Rappresenta un tag
Con element s'intende, come già accennato, ciascun'elemento della
pagina caratterizzato da un tag, perciò, nelle sintassi sotto proposte,
ogni volta che s'incontra element si dovrà intendere un generico
elemento, come può essere uno di quelli restituiti dai metodi
getElementById e getElementsByTagName. I metodi per
element, si occupano per lo più di gestire e manipolare le
caratteristiche d'ogni singolo elemento, come recuperare, settare e
rimuovere gli attributi dell'elemento stesso. Prima però menzioniamo un
metodo già visto:
- getElementsByTagName: è lo stesso visto per document,
ed ha quindi la stessa sintassi e la stessa semantica. In questo
caso però ritorna la lista degli elementi caratterizzati dal tag
specificato contenuti all'interno dell'elemento richiamato e non
tutti quelli presenti nella pagina.
- setAttribute: permette di creare un nuovo attributo per
l'elemento specificato. Qualora l'attributo sia già presente, il
metodo sovrappone il nuovo valore all'attributo in questione. La
sintassi è:
element.setAttribute("nome_attributo", "valore_attributo")
dove nome_attributo è il nome dell'attributo che deve
essere inserito o eventualmente modificato e valore_attributo
è il valore da settare all'attributo specificato.
- getAttribute: con questo metodo si recupera il valore
dell'attributo passato come argomento. La sintassi è:
element.getAttribute("nome_attributo")
dove nome_attributo è il nome dell'attributo di cui si
vuole recuperare il valore.
- removeAttribute: con questo metodo, si rimuove
l'attributo passato come parametro. Qualora l'attributo abbia un
valore di default, sarà questo il nuovo valore assunto
dall'attributo. La sintassi è:
element.removeAttribute("nome_attributo")
dove nome_attributo è il nome dell'attributo che si vuole
eliminare.
- tagName: utile proprietà degli elementi, che evidenzia il
binomio elemento-tag; restituisce il nome del tag dell'elemento
associato. La sua sintassi è, come per tutte le proprietà:
element.tagName
Passiamo ora ad esaminare i metodi riguardanti i nodi, dopodiché avremo
tutti gli strumenti per addentrarci nel lavoro.
L'OGGETTO NODE
Rappresenta un tag, un testo, un commento o un attributo
Per definizione con node s'intende l'interfaccia fondamentale del
modello ad oggetti del documento HTML. Possiede, infatti, un set di
attributi e metodi che consentono di scorrere le parentele tra i vari
nodi risalendo e addentrandosi nella gerarchia della pagina.
Infatti, nell'accezione di nodo, ricadono non solo i vari elementi, che
possono a loro volta avere elementi figli o attributi, ma anche
particolari componenti di una pagina, come il testo o i commenti. Questi
ultimi sono elementi "atipici", perché non possono avere attributi né
includere altri elementi, perciò costituiscono gli ultimi anelli della
struttura gerarchica del documento; sarebbero nodi irraggiungibili con i
metodi visti finora.
In questa sezione mostrerò i metodi e le proprietà inerenti ogni node,
grazie ai quali è possibile scorrere la struttura della pagina per
recuperare e manipolare ogni nodo.
Cominciamo con le principali proprietà:
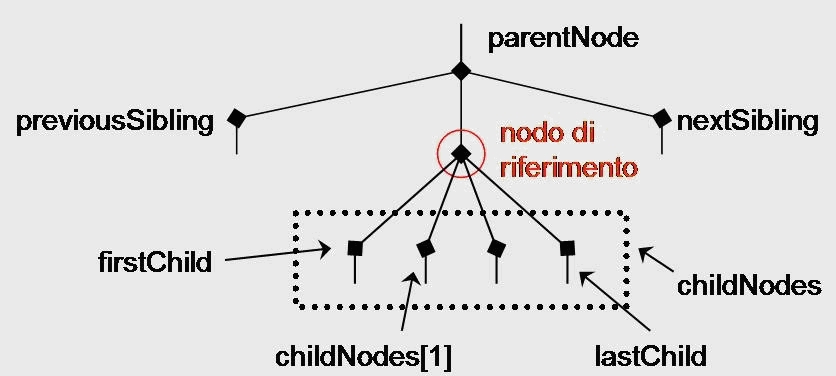
- childNodes: questa collezione contiene tutta la lista dei nodi figli del nodo al
quale è applicata la proprietà. Un nodo figlio (child) è un nodo
contenuto in quello considerato ed è quindi nel livello gerarchico
immediatamente inferiore.
Tecnicamente childNodes è un array che restituisce i nodi figli del nodo
in esame. Qualora il nodo non possegga figli, la proprietà restituisce
un array vuoto. La sua sintassi è:node.childNodes
Come ogni array, possiede a sua volta la proprietà length, ed è
possibile accedere ai singoli nodi "figli", utilizzando la consueta
sintassi dei vettori. Ad esempio, per recuperare il secondo figlio di un
nodo, si scriverà:
node.childNodes[1]
- firstChild: questa proprietà restituisce il primo figlio del nodo al quale è
applicata. Se il nodo non è presente restituisce null.
La sintassi è:
node.firstChild // equivale a: // node.childNodes[0]
- lastChild: questa proprietà restituisce l'ultimo figlio del nodo al quale è
applicata. Corrisponde all'elemento con indice uguale a length-1 della
collezione childNodes. Se il nodo non è presente restituisce null.
La sintassi è:node.lastChild // equivale a: // node.childNodes.length-1
- nextSibling: restituisce il nodo che segue quello al quale è applicato, per così
dire, restituisce il "fratello minore" del nodo in questione. Se il nodo
seguente non esiste, la proprietà restituisce null.
La sintassi è:
node.nextSibling
- previousSibling: questa proprietà restituisce il nodo precedente quello al quale è
applicato, cioè restituisce il "fratello maggiore" del nodo in
questione. Se il nodo precedente non esiste, la proprietà restituisce null.
La sintassi è:
node.previousSibling
- parentNode: restituisce il nodo che contiene quello al quale è applicato, ossia il
"padre" del nodo in questione. Se il nodo da restituire non esiste, la
proprietà restituisce null.
La sintassi è:
node.parentNode
Vi potrete adesso chiedere quale nodo non abbia un padre. La risposta
più immediata è: document, proprio perché è il nodo che contiene tutti
gli altri, è il capostipite della catena di parentele. Ma non è il solo.
Si pensi ad esempio al nodo di testo creato in precedenza, finché non
sarà inserito nella struttura gerarchica della pagina, non avrà alcun
nodo parent.
Per meglio comprendere le proprietà appena descritte ci sarà d'aiuto
questa
illustrazione.
- nodeValue: restituisce il valore del nodo. Il valore di ritorno dipende dal tipo di
nodo in questione, in particolare, per i tag, il valore ritornato è null,
mentre è il testo per i nodi di testo.
La sintassi è:
node.nodeValue
Passiamo a questo punto a descrivere i principali metodi applicabili ai
nodi. Cominciamo con un metodo che consente di stabilire se un nodo ne
contiene altri.
- hasChildNodes: questo metodo permette di verificare se un nodo possegga o meno dei
figli. Restituisce un valore booleano relativo al risultato della
verifica: se il nodo contiene altri nodi restituisce true altrimenti
false. La sintassi è:
node.hasChildNodes()
- appendChild: il metodo inserisce un nuovo nodo alla fine della lista dei figli del
nodo al quale è applicato.
La sintassi è:node.appendChild(nodo) dove
nodo è, per l'appunto, il nodo che si vuole inserire.
- insertBefore: questo metodo consente di inserire un nuovo nodo nella lista dei figli
del nodo al quale è applicato, appena prima di un nodo specificato.
La sua sintassi è:
node.insertBefore(nodo_inserito, nodo_esistente) dove
nodo_inserito è il nodo che si vuole inserire nella lista dei figli di
node, nodo_esistente è il nodo della lista dei figli di
node prima del quale
si vuole inserire il nuovo nodo. Continuando nella metafora delle
parentele, viene inserito un nuovo figlio di node che è il fratello
maggiore del nodo_esistente specificato.
- replaceChild: questo metodo consente di inserire un nuovo nodo al posto di un altro
nella struttura della pagina. La sua sintassi è:
node.replaceChild(nuovo_nodo, vecchio_nodo) dove
nuovo_nodo è il nuovo nodo che si vuole inserire al posto
del vecchio e vecchio_nodo è il nodo che si vuole rimpiazzare con il nuovo.
- removeChild: il metodo elimina e restituisce il nodo specificato dalla lista dei
figli del nodo al quale è applicato. La sua sintassi è:
node.removeChild(nodo_da_rimuovere) dove
nodo_da_rimuovere è il nodo che viene rimosso e restituito dal metodo.
- cloneNode: spesso può essere utile poter duplicare un
nodo, con tutti i suoi attributi, e tutti i suoi figli senza
dover ripercorrere tutti i passi che sono serviti per la sua
creazione. È questo lo scopo di questo metodo, infatti permette di duplicare un nodo già esistente, offrendo la
possibilità di scegliere se duplicare il singolo nodo, o anche tutti i
suoi figli. Dopodiché il metodo ritorna il nodo clone. La sua sintassi
è:
node.cloneNode(figli) dove figli (true/false) è un valore booleano che determina se clonare tutti
i figli insieme al nodo al quale è applicato il metodo (true), oppure se
clonare il solo nodo (false).
LA PROPRIETA' INNERHTML
Non standard, ma supportato
Un'utile alternativa può essere l'uso della proprietà innerHTML per gli
elementi: pur non essendo una proprietà standard (ma creata dalla
Microsoft), fornisce comode soluzioni per la creazione di nuovi elementi
della pagina. Anche se il gruppo di lavoro per il DOM del W3C non ha
implementato questa proprietà per lo standard pubblicato, essa si è
rilevata troppo pratica e popolare per essere ignorata dai produttori di
browser. La tabella sottostante riporta un elenco dei principali browser
di nuova generazione che supportano tale proprietà.
|
Browser |
Windows/Mac |
Linux |
|
Internet Explorer |
Netscape |
Opera |
FF + |
FF + |
Ko 2 |
Ga 1 |
|
element.innerHTML |
4+ |
4+ |
NO |
1+ |
1+ |
2+ |
1+ |
Il valore della proprietà è una stringa contenente tag HTML e altro
contenuto, come se apparisse in un documento HTML all'interno dei tag
dell'elemento corrente. Questo permette di unire la semplicità di
scrivere del familiare codice HTML al vantaggio della dinamicità
dell'uso dei metodi.
La sua sintassi è: node.innerHTML = codice_HTML
dove codice_HTML è il codice HTML da inserire all'interno del nodo.
Occorre precisare che, a differenza dei metodi W3C per la creazione di
nuovi elementi, innerHTML non restituisce alcun riferimento ai nodi
creati, permettendo, d'altro canto, di inserire nuovi elementi al volo
usando la più compatta e comoda sintassi HTML.
Questa proprietà torna utile soprattutto quando si vuole inserire
paragrafi con particolari formattazioni, che obbligherebbero, con la
sintassi W3C, alla stesura di un codice un po' prolisso e a volte
contorto.
Occorre inoltre fare attenzione a dove inserire il nuovo codice HTML,
poiché la proprietà innerHTML sostituisce tutto il contenuto del nodo al
quale viene applicata, con il nuovo codice specificato. Perciò,
l'esempio seguente sostituirà completamente il contenuto del tag BODY
con quello specificato:document.getElementsByTagName("BODY").item(0).innerHTML = "<p><b>ciao</b></p><a href='pagina.html'>Vai a..</a>";
|
{kind=link}